
Docker:第二篇 使用一百行代码实现一个Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
文章来源
Build Your Own Container Using Less than 100 Lines of Go
前言
2013年3月,Docker的发布与开源使得软件开发行业在打包和部署现代应用的方式发生了巨大的改变。在Docker之后,有许多相互竞争,相互补充和相互支持的容器技术相继问世,这导致了在虚拟容器这一领域的繁荣,同时也引发了很多问题。本系列文章的目的是消除一些人在使用时候的困惑,同时解释Docker在企业中的实际使用情况。
本系列文章首先介绍了Docker背后的核心技术以及开发人员目前是如何使用的,然后研究了在企业中部署Docker的核心挑战,例如将容器化整合到持续集成和持续交付管道中,以及加强监控以支持不断变化的工作负载和潜在的过渡性。该系列最后展望了容器化的未来,并讨论了联合内核技术目前在前沿组织中发挥的作用。
很多人经常用类比来解释一个新的事物,可是类比的问题在于,当你听到类比的时候,你的大脑往往会宕机。有些人可能会说,软件体系结构“就像”构建体系结构。不,事实并非如此,这个类比听起来很好,但可以说导致了相当多的谬误。与此相关的是,软件集装箱化通常被标榜为提供移动软件的能力,“就像”集装箱移动货物一样。不完全是。或者至少,它是,但这个类比失去了很多细节。
集装箱和软件容器确实有很多共同之处。集装箱具有标准的形状和尺寸,可以实现强大的规模经济和标准化。软件容器承诺了许多相同的好处。但是,这是一个表面的类比——一个目标而不是事实。
要真正理解软件世界中的容器是什么,我们需要了解制作容器需要做什么。这就是本文要解释的。在这个过程中,我们将讨论容器vs容器化,linux容器(包括名称空间,cgroup和分层文件系统),然后我们将从头开始构建一个简单的容器的一些代码,最后讨论这一切的真正含义。
什么是容器?
我们来玩个游戏,现在在你脑子里,告诉我什么是“容器”。做了什么?好的。让我看看我能不能猜出你说了什么
你可能会说其中一个或多个:
- 一种资源共享的方式
- 处理隔离
- 有点像轻量级虚拟化
- 将根文件系统和元数据打包在一起
- 有点像chroot监狱
- 有东西,有东西,船运集装箱什么的
- 无论码头工人做什么
从名字上,我们可以知道很多事情。“容器”这个词已经开始被用于很多(有时是重叠的)概念。它被用于容器化的比喻,以及用于实现它的技术。如果我们把这些分开考虑,我们会得到一个更清晰的画面。所以,让我们来谈谈容器的原因,然后再谈谈如何。(然后我们再回到为什么)。
写在前面
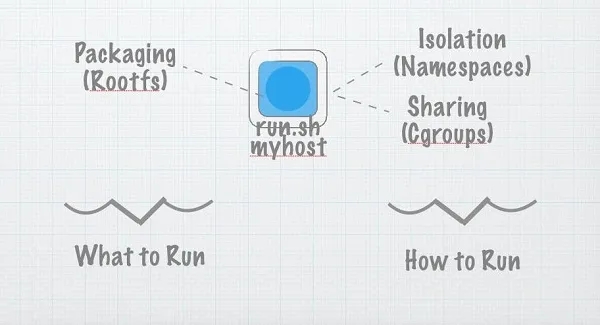
假如我们想要再服务器上运行一个程序run.sh,我们要做的是把它复制到远程服务器上,然后运行它。然而,在远程计算机上运行任意代码是不安全的,而且很难管理和扩展。所以我们发明了虚拟服务器和用户权限。现在,事情就好办了。
但考虑到run.sh有依赖性。它需要在主机上存在某些库。而且它在远程和本地的工作方式也不尽相同。所以我们发明了AMI(亚马逊机器镜像)和VMDK(VMware镜像)以及Vagrantfiles等等,一切似乎都很顺利。
好吧,他们是有点好。这些捆绑物很大,而且很难有效地运送它们,因为它们不是非常标准化的。因此,我们发明了缓存。
而事情是好的。
缓存是使Docker镜像比vmdks或vagrantfiles更有效的原因。它让我们可以通过一些共同的基础镜像来运送delta,而不是到处移动整个镜像。这意味着我们有能力将整个环境从一个地方运到另一个地方。这就是为什么当你 "docker run whatever "时,它几乎是立即启动的,尽管everever描述的是整个操作系统的镜像。我们将在(第N节)中更详细地讨论这个工作原理。
而且,真的,这就是容器的作用。它们是关于捆绑依赖关系的,所以我们可以以可重复的、安全的方式来运送代码。但这是一个高层次的目标,而不是一个定义。所以,让我们来谈谈现实。
构建一个容器
那么(这次是真的!)什么是容器?如果创建一个容器就像创建_容器的系统调用一样简单,那就更好了。其实不然。但说实话,这很接近。
要在低层次上谈论容器,我们必须谈论三件事。这些东西是命名空间、c组和分层文件系统。还有其他的东西,但这三样东西构成了大部分的魔法。
命名空间(Namespaces)
命名空间提供了在一台机器上运行多个容器所需的隔离,同时给每个容器提供了看起来像它自己的环境。在写这篇文章的时候,有六个命名空间。每个命名空间都可以独立请求,相当于给一个进程(及其子进程)一个机器资源子集的视图。
命名空间:
- PID pid命名空间给进程及其子进程提供了他们自己对系统中的一个子集的看法。可以把它看作是一个映射表。当一个pid命名空间中的进程向内核询问进程列表时,内核会在映射表中查找。如果该进程存在于该表中,则使用映射的ID来代替真实的ID。如果它不存在于映射表中,内核会假装它根本不存在。pid命名空间使在其中创建的第一个进程成为pid 1(通过将其主机ID映射为1),使容器中出现了一个孤立的进程树。
- MNT 在某种程度上,这个是最重要的。挂载命名空间为包含在其中的进程提供了它们自己的挂载表。这意味着它们可以装载和卸载目录而不影响其他命名空间(包括主机命名空间)。更重要的是,结合pivot_root系统调用–我们将看到–它允许一个进程拥有自己的文件系统。这就是我们如何让一个进程认为它是在ubuntu、busybox或alpine上运行的–通过调换容器看到的文件系统。
- NET 网络命名空间为使用它的进程提供了自己的网络堆栈。一般来说,只有主网络命名空间(当你启动计算机时启动的进程使用的网络命名空间)实际上会有任何真正的物理网卡连接。但我们可以创建虚拟的以太网对–链接的以太网卡,其中一端可以放在一个网络命名空间,另一端放在另一个网络命名空间,在网络命名空间之间创建一个虚拟链接。这有点像在一台主机上有多个IP堆栈在互相交谈。通过一点路由魔法,这允许每个容器与现实世界对话,同时将每个容器隔离在自己的网络栈中。
- UTS UTS命名空间使其进程对系统的主机名和域名有自己的看法。进入UTS命名空间后,设置主机名或域名不会影响其他进程。
- IPC IPC 名称空间隔离了各种进程间通信机制,如消息队列。更多细节见命名空间文档。
- USER 用户命名空间是最近增加的,从安全角度看可能是最强大的。用户命名空间将一个进程看到的UID映射到主机上不同的UID(和GID)集合。这是很有用的。使用用户命名空间,我们可以将容器的根用户ID(即0)映射到主机上一个任意的(无特权的)UID。这意味着我们可以让一个容器认为它有root权限–我们甚至可以在容器特定的资源上给予它类似root的权限–而实际上在root命名空间中并没有给予它任何特权。容器可以自由地以 uid 0 的身份运行进程–这通常是拥有 root 权限的同义词–但内核实际上是将这个 uid 隐蔽地映射到一个没有特权的真实 uid。大多数容器系统不会将容器中的任何uid映射到调用命名空间中的uid 0:换句话说,容器中根本没有一个uid拥有真正的根权限。
大多数容器技术将用户的进程放入上述所有的命名空间,并初始化命名空间以提供标准环境。例如,这相当于在容器的隔离网络命名空间中创建一个初始互联网卡,与主机上的真实网络相连接。
控制组群(CGroups)
老实说,控制组群可以自己写一整篇文章(我保留写一篇的权利!)。我将在这里简要地讨论它们,因为一旦你理解了这些概念,你就可以在文档中直接找到很多东西。
从根本上说,cgroups将一组进程或任务的ID收集在一起,并对它们进行限制。在命名空间隔离进程的地方,控制组群在进程之间执行公平的(或不公平的–由你决定,疯狂吧)资源共享。
控制组群被内核暴露为一个特殊的文件系统,你可以加载。你可以通过简单地将进程ID添加到任务文件中,将一个进程或线程添加到一个控制组中,然后通过编辑该目录中的文件来读取和配置各种值。
分层文件系统(Layered Filesystems)
命名空间和控制组群是容器化的隔离和资源共享方面。它们是大容器的边缘和Docker上的保安。分层文件系统是我们如何有效地移动整个机器镜像的方法:它们是“船”漂浮而不是下沉的原因。
在一个基本层面上,分层文件系统相当于优化了为每个容器创建根文件系统副本的调用。有许多方法可以做到这一点。Btrfs在文件系统层使用写时拷贝。Aufs使用 “联合挂载”。既然有这么多方法来实现这一步,本文将只使用一些简单得可怕的方法:我们真的会做一个拷贝。这很慢,但它是有效的。
构建一个容器
1.构建框架
让我们先把粗略的框架做好。相信你已经安装了最新版本的golang编程语言SDK,然后打开一个编辑器,并复制以下代码:
1 | package main |
那么这是做什么的呢?我们从main.go开始,读取第一个参数。如果是’run’,我们就运行父方法,如果是child(),我们就运行子方法。父方法运行/proc/self/exe,这是一个特殊的文件,包含当前可执行文件的内存镜像。换句话说,我们重新运行自己,但把child作为第一个参数。
这种疯狂是什么?嗯,现在,没有什么。它只是让我们执行另一个程序,执行一个用户要求的程序(在os.Args[2:]中提供)。不过,通过这个简单的脚手架,我们可以创建一个容器。
添加命名空间
为了给我们的程序添加一些命名空间,我们只需要添加一行。行。在parent()方法的第二行,只要添加这一行,告诉go在运行子进程时传递一些额外的标志。
1 | cmd.SysProcAttr = &syscall.SysProcAttr{ |
如果你现在运行你的程序,你的程序将在UTS、PID和MNT命名空间内运行。
根文件系统
目前,你的进程是在一组孤立的命名空间中(在这一点上,请随意尝试将其他命名空间添加到你的Cloneflags上面)。但是文件系统看起来和主机是一样的。这是因为你在一个挂载命名空间中,但初始挂载是从创建命名空间中继承的。
让我们来改变这一点。我们需要以下四个简单的行来交换成一个根文件系统。把它们放在child()函数的开头。
1 | must(syscall.Mount("rootfs", "rootfs", "", syscall.MS_BIND, "")) |
最后两行是重要的部分,它们告诉操作系统将当前目录/移到rootfs/oldrootfs,并将新的rootfs目录交换到/。在pivotroot调用完成后,容器中的/目录将指向rootfs。(绑定挂载调用是为了满足pivotroot命令的一些要求–操作系统要求pivotroot用于交换两个不属于同一树的文件系统,绑定挂载rootfs到自己身上实现了。是的,这很傻)。
初始化容器
在这一点上,你有一个运行在一组隔离命名空间中的进程,有一个你选择的根文件系统。我们跳过了c组的设置,虽然这很简单,我们也跳过了根文件系统的管理,让你有效地下载和缓存我们`pivotroot’到的根文件系统镜像。
我们也跳过了容器的设置。你在这里得到的是一个孤立命名空间的新容器。我们通过透视到rootfs设置了挂载命名空间,但其他命名空间都有其默认内容。在一个真正的容器中,我们需要在运行用户进程之前为容器配置 “世界”。因此,例如,我们要设置网络,在运行进程之前交换到正确的uid,设置我们想要的任何其他限制(例如放弃能力和设置rlimits),等等。这很可能使我们超过100行。
结合起来
所以在这里,一个超级超级简单的容器,不到100行的样子。很明显,这是有意为之的简单。如果你在生产中使用它,你就疯了,更重要的是,你要靠自己。但我认为,看到一些简单的、黑客式的东西,可以让我们对发生的事情有一个真正有用的认识。因此,让我们看一下清单A。
1 | package main |
所以,这意味着什么?
在这里,我将会有一点争议。对我来说,容器是一种奇妙的方式,可以在周围运送东西,并以良好的隔离性廉价运行代码,但这并不是谈话的结束。容器是一种技术,而不是一种用户体验。
作为一个用户,我不想把容器推到生产中去,就像一个使用amazon.com的购物者想给码头打电话来组织货物的运输一样。容器是一种非常好的技术,可以建立在其之上,但我们不应该被移动机器图像的能力所干扰,而忽略了建立真正伟大的开发者体验的需要。
建立在容器之上的平台即服务(PaaS),如Cloud Foundry,从基于代码的用户体验开始,而不是容器。对于大多数开发人员来说,他们想做的是推送他们的代码并让它运行。在幕后,Cloud Foundry–以及其他大多数PaaS–将这些代码用于创建一个可扩展和管理的容器化镜像。在Cloud Foundry的情况下,这需要一个构建包,但你也可以跳过这一步,推送一个由Docker文件创建的Docker镜像。
有了PaaS,容器的所有优势仍然存在–一致的环境、有效的资源管理等–但通过控制用户体验,PaaS既可以为开发者提供更简单的用户体验,又可以执行一些额外的技巧,如在有安全漏洞时修补根文件系统。更重要的是,平台提供了诸如数据库和消息队列之类的东西,作为你可以与你的应用程序绑定的服务,消除了将一切视为容器的必要性。
所以,我们已经研究了什么是容器。现在,我们应该用它们做什么呢?





