
机器学习:第一篇 LSTM神经网络简单入门
One day ladies will take their computers for walks in the park and tell each other, “My little computer said such a funny thing this morning”.
—Alan Turing
写在前面
这是一个入门级的讲解,所以并不需要担心自己会看不懂,而且LSTM在神经网络中属于那种比较简单的模型。首先我们会简单讲解一下LSTM的原理,然后再结合一个例子。
软件要求
anaconda 3(64-bit) (anaconda是一个包管理和环境管理软件,因为我们在平时的使用中难免会遇到有些古老的包不支持最新的Python版本,或者是有些项目会使用到特定版本的模块,这时候就需要用到anaconda了)
Python IDE (直接使用Python自带的IDE也可以,但是好像并不好用,推荐使用anaconda自带的Jupyter Note,也可以使用Pycharm,我自己用的IDE是VScode)
tensorflow 2.1 (一般在anaconda自带的powershell里面pip install tensorflow==2.1.0就可以了)
numpy (在安装tensorflow的时候会自动安装numpy)
什么是LSTM?
LSTM(Long Short-Term Memory Networks)是长短期记忆网络,是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。(关于lstm的原理等等我就不说了,大家可以去百度上,有很多介绍lstm原理的帖子,总之就是lstm比其他的神经网络更接近于人类)
【译】理解LSTM(通俗易懂版)
使用LSTM实现二进制加法
实践出真理,理论课太枯燥无味,直接上实践课吧。
模块导入
由于项目过于简单,所以一共就两个模块。。。
1 | import tensorflow as tf |
参数定义
1 | binary_dim = 8 |
首先定义一下二进制的长度,binary_dim=8,表示序列长度。所以最大的数字就是largest_number = 2*8 = 256,所以本文中用到的数字都不能超过256
再定义一个int2binary的字典,这个字典里面存放的是按顺序的二进制位,例如int2binary[3] = [0,0,0,0,0,0,1,1]
然后np.unpackbits是将整数转成二进制数,np.uint8是无符号8位整型,axis就是用来指定需要操作的数组的维数。
lstm_size表示LSTM的个数,就是隐层中神经元的数量。
lstm_layers表示隐藏层的数量。
steps表示迭代的次数,次数越多,训练越准确。
接着是我们要用到的几个函数。
十进制转二进制
1 | def binary_generation(numbers, reverse = False): |
这个函数的作用是直接返回一个长度为8的无符号整型列表,将numbers中的每个数转换成二进制,并返回列表,reverse是翻转二进制数,因为二进制加减都是从后往前加。
随机生成数据
1 | def batch_generation(largest_number): |
这个函数的作用就是随机生成两个从0到128的随机数,并计算他们的和,然后返回他们的二进制形式,其中输入的两个数的和进行堆叠。
二进制转十进制
1 | def binary2int(binary_array): |
这个不解释,就是普通的二进制转十进制。
下面就是进行算法流图的搭建了,tensorflow的思想都是先把神经网络的结构搭建好,再进行计算,我们一般将这种先搭建再计算的方式叫做静态流图。静态流图与我们正常的Python逻辑走一步计算一步不同。所以在2017年发布的Pytorch采用了动态流图的方式,每一步都是计算完之后在传递给下一步计算,我们将他叫做动态流图,而且在tensorflow2.0中也改为了动态流图。
因为这篇文章的项目是在大二写的了,那时候TensorFlow还在使用静态流图,所以这里的算法都是比较古老一点的。关于新版本动态流图的做法,我会在以后的文章中讲述。
神经层的搭建
数据的输入与输出
1 | x = tf.compat.v1.placeholder(tf.float32, [None, binary_dim, 2], name='input_x') |
placeholder函数就是用来占位的意思,先在内存中请求这样一个位置,然后之后再填入数据
在新版本的TensorFlow中,动态流图已经不需要再请求占位了。
keep_prob是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
搭建LSTM层(看成隐层)
1 | lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) |
每一层有lstm_size神经元,然后一共有lstm_layers层
初始化神经网络
1 | initial_state = cell.zero_state(batch_size, tf.float32) |
初始化,很简单。
前向传播,得到隐藏层的输出
1 | outputs, final_state = tf.nn.dynamic_rnn(cell, x, initial_state=initial_state) |
建立输出层
1 | weights = tf.Variable(tf.truncated_normal([lstm_size, 1], stddev=0.01)) |
weights是一个以标准差为0.01的正态分布初始化一个形状为[lstm_size,1]的张量
损失值与优化器
1 | cost = tf.losses.mean_squared_error(y_, predictions) |
mean_squared_error是用来计算输出值与估计值之间的均方误差。
我们使用的优化器是AdamOptimizer,优化器就是在神经网络计算中,梯度下降的方式。AdamOptimizer可控制学习速度,经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
还有很多其他的优化器:
Tf.train.AdadeltaOptimizer
Tf.train.AdagradDAOptimizer
Tf.train.AdagradOptimizer
Tf.train.AdamOptimizer
Tf.train.FtrlOptimizer
Tf.train.GradientDescentOptimizer
Tf.train.MomentumOptimizer
Tf.train.ProximalAdagradOptimizer
Tf.train.ProximalGradientDescentOptimizer
Tf.train.RMSPropOptimizer
Tf.train.SyncReplicasOptimizer
等。。。
运行与测试
1 | with tf.Session() as sess: |
tf.Session()创建一个用来运行模型的环境,需要请求内存空间,所以在使用完之后要sess.close()来释放内存,这里使用with…as…来释放,避免在运行出错的时候无法释放内存资源。
后面的运行模型以及模型测试都是在该环境中,所以记得后面的代码全部缩进4格。
运行模型
1 | tf.global_variables_initializer().run() #初始化所有变量 |
input_x以及input_y是随机生成的输入输出数据。
iteration是静态变量计算运行次数。
测试模型
1 | #输入数据,转换成二进制数组 |
输出结果
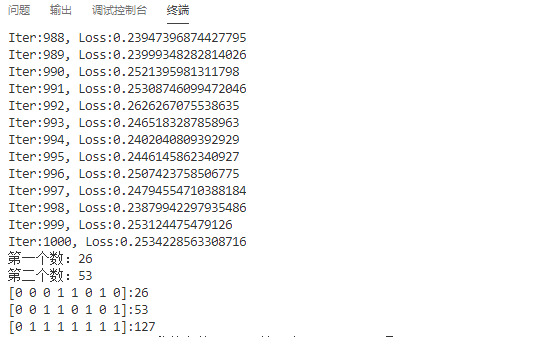
只运行了steps = 1000的结果,理论上只需要运行128*128 = 16384次就可以获得100%的准确率,在实际中,运行3000次左右就可以有99%的准确率吧,所以并不需要这么多。
这是机器学习系列的第一篇文章,也是最后一篇静态流图的文章,至于以后会不会再更新机器学习系列,看我的心情吧。:stuck_out_tongue_winking_eye:
如果各位有看不懂的地方欢迎在评论区提出,我会的,我都会回答的。:grin:





