
web开发:第一篇 一个简单的socket套接字通讯
最近看了很多服务器与客户端通讯的程序以及架构,这里简单的总结一下。(资料大多来源于网上)
写在前面
现在假设一个非常非常简单的场景,我们有两个设备或者是程序之间需要通信。
如果这两个设备靠的很近,或者说在同一个区域内,那么我们可以使用信号线将他们相连接,并且通过高低电平或者是差分信号进行传输二进制数据。并且拟定一个简单的通信协议就可以进行通信了,例如这个文章里面写的。简单的通信协议
但是如果他们相隔较远,那么我们就可以依靠网络来进行通信,因为世界是由网络所连接在一起的,只要在任何有网络的地方都可以实现设备之间的通信。我们的网络是基于TCP/IP协议族设计的通讯协议,这里简单的抄一张网上的图来回顾一下TCP/IP协议族的通讯流程。
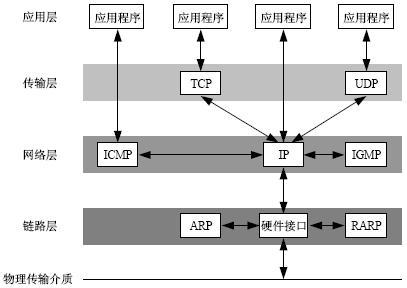
不同于OSI模型,TCP/IP协议参考模型把所有的TCP/IP系列协议归类到四个抽象层中。
每一抽象层建立在低一层提供的服务上,并且为高一层提供服务。
但是,直接进行TCP/UDP通信的话,这些操作还是太复杂了,我们需要一个更加抽象的方式,来提供简单易用的接口来供应用层使用。从而使得在网络上的两个设备的进程之间相当于可以直接进行通信,我们把这种封装加做套接字(socket)。
socket
socket起源于UNIX,在Unix一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
socket是"打开—读/写—关闭"模式的实现,以使用TCP协议通讯的socket为例,其交互流程大概是这样子的。
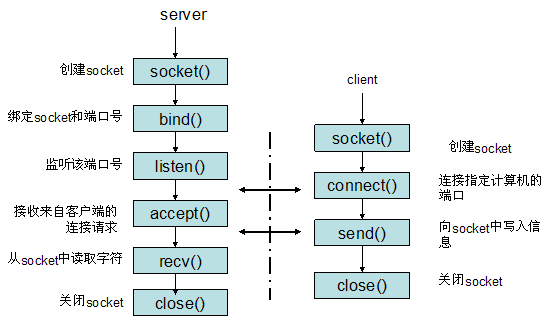
我们知道,在系统内部,为了能够唯一的标识两个进程,那么我们可以使用PID来标识进程,但是在网络上,我们得使用别的办法来标识,socket的方法是通过 ip + 协议 + 端口的形式来唯一的标识在网络上的进程。
可以仔细理解客户端与服务端的连接建立过程以及连接断开过程,这个就是大名鼎鼎的TCP三次握手协议。
第一次:客户端打开socket,根据服务器ip地址和端口号试图连接服务器socket。
第二次:服务器socket接收到客户端socket请求,被动打开,开始接收客户端请求,直到客户端返回连接信息。这时候socket进入阻塞状态,所谓阻塞即accept()方法一直到客户端返回连接信息后才返回,开始接收下一个客户端谅解请求。
第三次:客户端连接成功,向服务器发送连接状态信息。
简单实现一个socket
这里使用python的socket的库来实现一个简单的socket。
sever
服务端程序
1 | import socket |
client
客户端程序
1 | import socket |
总结
客户端连接上套接字之后,发送一个信息给服务端,服务端将信息返回,然后关闭连接,客户端再关闭连接。假如说要连续通讯,也很简单,在连接上之后,用loop包裹住通讯的部分就可以实现连续的通讯了。
socket通讯的缺点
因为服务端程序是单线程通讯的,所以当请求占据了服务端的进程之后,就没有办法处理其他的请求了。所以这个时候我们进行一点点的改进措施,每来一个请求,我们就fork一个进程。
1 | while True: |
使用多线程实现多连接。
1 | while True: |
但多进程模型处理不好会出现僵尸进程和孤儿进程。
Zombie Process 僵尸进程
僵尸进程,在终止之后任然在系统保留着进程表记录的进程.
简单来说就是子进程已经结束了,但是父进程并没有对子进程进行回收。例如,当我们的客户端断开了连接以后,服务端没有对客户端进行处理,导致客户端一直占用着内存,随着新连接的客户端越来越多,会导致僵尸进程不断产生。
实现一个简单的僵尸进程。在linux系统下运行。
1 | import time,sys |
在程序还没退出的时候,在终端输入ps -aux|grep python,就可以看到有一个Z+的进程表示僵尸进程。
因此父进程需要处理SIGCHILD信号来收集退出的子进程的信息。
1 | def childHandler(signum, stackframe): |
孤儿进程
而孤儿进程与僵尸进程相反,父进程先于子进程结束。这个时候,子进程就会变成孤儿进程,从而被linux系统的init进程也就是PID=1进程收养,完成状态收集工作。
我们也可以利用这个特性,创建一个不被终端关闭所影响的进程,也就是进程守护(daemon)。
先演示一下os.fork()是怎么fork一个子进程出来的。
1 | import os,time |
执行os.fork之后,程序会在这里一分为二,其中对于子进程来说,os.fork的返回值是0,对于父进程来说,os.fork的返回值是子进程的返回值。
而如果后面再有os.fork,只要运行了os.fork的进程又会在这里一分为二,再次产生子进程,运行os.fork的进程是产生新的进程的父进程,同时也是它的父进程的子进程。以此类推。所以一个进程既可以是子进程,也可以是新产生的子进程的父进程。
最后
假如拥有优秀的内存回收机制,以及各种处理手段,我们依然可以有效的避免僵尸进程还有孤儿进程,实现一对多的正常通讯。
在最原始的CGI程序中,就是用这种fork子进程的方式来与客户端进行通信的,得益于操作系统优秀的内存调度机制,CGI可以有效避免僵尸进程和孤儿进程,不过CGI也存在着非常多的局限性。
至于CGI是怎么实现的,且听下回分解。





