
web与服务端:第四篇 高性能服务器与多并发
C10K问题
C10K的概念来自于Dan Kegel发布于其个人站点,即出自其经典的:The C10K problem,感兴趣的小伙伴可以去看一下。
由来
前面我们说到,在传统的服务端,我们主要还是通过进程/线程的方式来处理请求,每来到一个请求,都要给他分配一个进程/线程。但是在操作系统中,线程/进程终究是有限的,当访问量过大的时候,例如10k问题,创建1w个进程,操作系统是不可能扛得住的。如果采用分布式的方法,也需要非常多的服务器,成本太高了,也是无法接受的。
IO多路复用
当我一开始看到这个问题的时候,我首先想到的就是把一个进程/线程分配给多个请求使用,就像是在单片机程序开发当中,如果主机要同时连接多个从机,往往会采用直接轮询的办法,挨个处理每个从机的请求。
1 | // 循环遍历 |
通过不断的遍历,轮询每个连接是否有数据,然后进行读取和处理请求。那这个效率肯定是很慢的。有没有办法可以简化这个轮询的状态?
这个时候,就会想到,使用一个集合来表示各个连接的状态,然后轮询这个集合,当状态发生变化的时候,则调用线程去处理这个网络连接,由于在Linux操作系统中,linux系统把所有网络请求以一个fd来标识,所以这个时候只需要用一个堵塞进程来轮询fd文件的集合就可以了,就像下图所示:
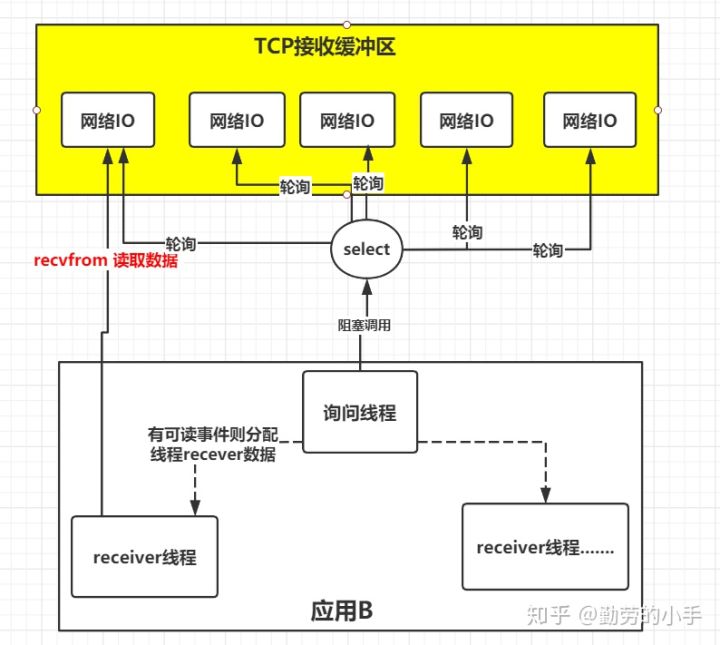
系统提供了一种函数可以同时监控多个fd的操作,这个函数就是我们常说到的select、poll、epoll函数,有了这个函数后,应用线程通过调用select函数就可以同时监控多个fd,select函数监控的fd中只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时询问线程再去通知处理数据的线程,对应线程此时再发起recvfrom请求去读取数据。
思考题:这个时候就会有不太聪明的小伙伴要问了,CPU用来监控fd的状态,那么网络IO是如何写入fd的?难道网络IO可以绕过CPU直接与内存交互?
select
进程通过将多个fd传递给select,阻塞在select操作上,select帮我们侦测多个fd是否准备就绪,当有fd准备就绪时,select返回数据可读状态,应用程序再调用recvfrom读取数据。
在系统中,select构造函数如下所示:
1 | /** |
官方的文档如下所示:
DESCRIPTION
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become “ready” for some class of I/O operation (e.g.,input possible). A file descriptor is considered ready if it is possible to perform the corresponding I/O operation (e.g., read(2)) without blocking.
当然,select问题也有:效率低,性能不太好。不能解决大量并发请求的问题。
它把1000个fd加入到fd_set(文件描述符集合),通过select监控fd_set里的fd是否有变化。如果有一个fd满足读写事件,就会依次查看每个文件描述符,那些发生变化的描述符在fd_set对应位设为1,表示socket可读或者可写。
Select通过轮询的方式监听,对监听的FD数量 t通过FD_SETSIZE限制。
两个问题:
1、select初始化时,要告诉内核,关注1000个fd, 每次初始化都需要重新关注1000个fd。前期准备阶段长。
2、select返回之后,要扫描1000个fd。 后期扫描维护成本大,CPU开销大。
epoll
epoll :在内核中的实现不是通过轮询的方式,而是通过注册callback函数的方式。当某个文件描述符发现变化,就主动通知。成功解决了select的两个问题,“epoll 被称为解决 C10K 问题的利器。”
1、select的“健忘症”,一返回就不记得关注了多少fd。api 把告诉内核等哪些文件,和最终监听哪些文件,都是同一个api。而epoll,告诉内核等哪些文件 和具体等哪些文件分开成两个api,epoll的“等”返回后,还是知道关注了哪些fd。
2、select在返回后的维护开销很大,而epoll就可以直接知道需要等fd。
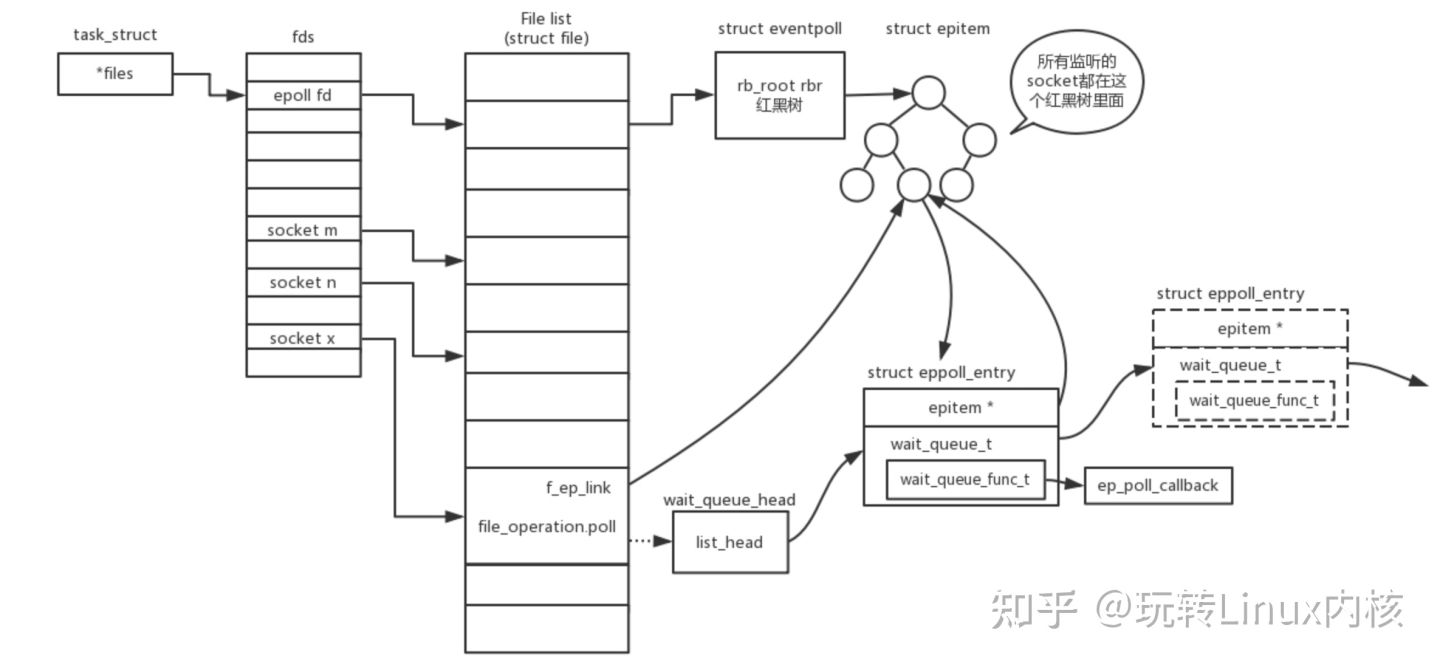
epoll的构造函数信息如下 所示:
1 | /** |
官方的文档如下所示:
DESCRIPTION
poll() performs a similar task to select(2): it waits for one of a set of file descriptors to become ready to perform I/O.
epoll获取事件的时候,无须遍历整个被侦听的描述符集,只要遍历那些被内核I/O事件异步唤醒而加入就绪队列的描述符集合。
epoll_create: 创建epoll池子。
epoll_ctl:向epoll注册事件。告诉内核epoll关心哪些文件,让内核没有健忘症。
epoll_wait:等待就绪事件的到来。专门等哪些文件,第2个参数 是输出参数,包含满足的fd,不需要再遍历所有的fd文件。
epoll是几乎是大规模并行网络程序设计的代名词,一个线程里可以处理大量的tcp连接,cpu消耗也比较低。很多框架模型,nginx, nodejs, 底层均使用epoll实现。
C10M问题
epoll 已经可以较好的处理 C10K 问题,但是如果要支持 10M 规模的并发连接,原有的技术就会有瓶颈了。从前面的C10K解决方案的演化过程中,我们可以看到,根本的思路是要高效的去阻塞,让 CPU可以干核心的任务。这意味着,不要让内核执行所有繁重的任务。将数据包处理、内存管理、处理器调度等任务从内核转移到应用程序高效地完成,让Linux只处理控制层,数据层完全交给应用程序来处理。
我觉得,处理C10M的问题可能有下面这些方法:
- 合理的分配线程,对线程进行进一步划分,充分利用每一个线程。
- 过去的技术主要针对的还是单核CPU,无法充分利用多核CPU的性能,如何提高多核的性能可扩展性,也是一个问题。
- TCP/IP协议设计于几十年前,主要是针对以前的网络环境较为复杂的情况设计,现在它们可能不太适合现在的的网络环境,根据现在的高并发需求重新设计新的IO协议或许可以解决。例如基于UDP的KCP协议。
- 远离操作系统,用户态和内核态之间的切换工作效率太低了,让用户程序远离操作系统,操作系统只进行控制,而不参与数据管理。
注:未来的十年,会有怎样的技术谁也说不准是吧,万一从别的地方降维打击了也说不定。
几个Python异步网络框架




协程
为了解决C10K问题,协程能够充分利用CPU的性能,效率比进程切换要高的多。协程,又称作Coroutine。从字面上来理解,即协同运行的例程,它是比是线程(thread)更细量级的用户态线程,特点是允许用户的主动调用和主动退出,挂起当前的例程然后返回值或去执行其他任务,接着返回原来停下的点继续执行。
我们常用的async/await语法糖就是一种协程。
1 | async def async_function(): |
Gevent
gevent是基于协程的Python网络库。特点:
- 基于libev的快速事件循环(Linux上epoll,FreeBSD上kqueue)。
- 基于greenlet的轻量级执行单元。
- API的概念和Python标准库一致(如事件,队列)。
- 可以配合socket,ssl模块使用。
- 能够使用标准库和第三方模块创建标准的阻塞套接字(gevent.monkey)。
- 默认通过线程池进行DNS查询,也可通过c-are(通过GEVENT_RESOLVER=ares环境变量开启)。
- TCP/UDP/HTTP服务器
- 子进程支持(通过gevent.subprocess)
- 线程池
gevent中的主要模式, 它是以C扩展模块形式接入Python的轻量级协程。 全部运行在主程序操作系统进程的内部,但它们被程序员协作式地调度。
在任何时刻,只有一个协程在运行。
区别于multiprocessing、threading等提供真正并行构造的库, 这些库轮转使用操作系统调度的进程和线程,是真正的并行。
同步与异步
并发的核心思想在于,大的任务可以分解成一系列的子任务,后者可以被调度成 同时执行或异步执行,而不是一次一个地或者同步地执行。两个子任务之间的 切换也就是上下文切换。
在gevent里面,上下文切换是通过yielding来完成的.
1 | import gevent |
运行结果:
1 | Synchronous: |
当然,基于协程的gevent还有很多其他的内容,这里就不展开了。在Python 3.4后出现了专门处理异步IO的标准库asyncio。
asyncio
asyncio是python 3.4中新增的模块,asyncio模块主要包括了:
- 具有特定系统实现的事件循环(event loop)
- 数据通讯和协议抽象(类似Twisted中的部分)- TCP,UDP,SSL,子进程管道,延迟调用和其他
- Future类
- yield from的支持
- 同步的支持
- 提供向线程池转移作业的接口
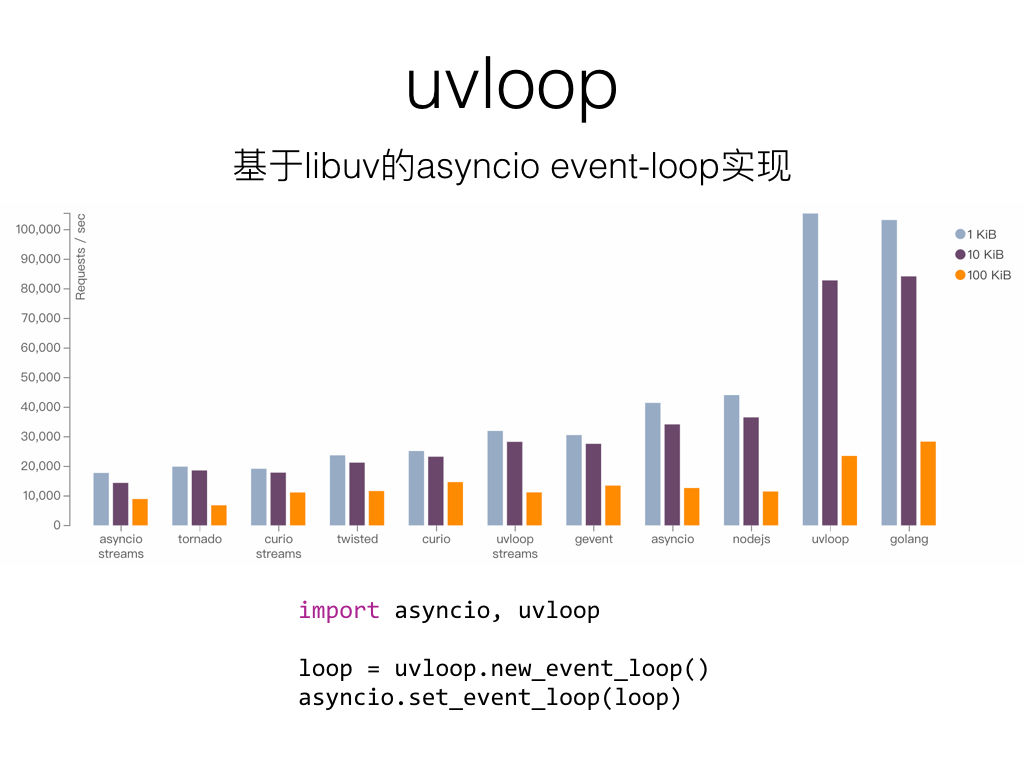
虽然asyncio成为标准库,但它使用方法却较为复杂,不便于使用,也有人提议要asyncio提供更简洁的接口,也有不少的替代库出现。
结语
随着异步IO、协程的兴起与服务器性能的提高,在服务器编程里面,涌现了非常多的Python的web库,像赫赫有名的Flask,uvloop等高性能的服务器框架。
当然,性能的提高是一方面,还有另一方面是易用性也是很重要的,例如被吹很火的FastAPI,以高性能,简单易用著称。
下一节深入展开学习一下FastAPI:





